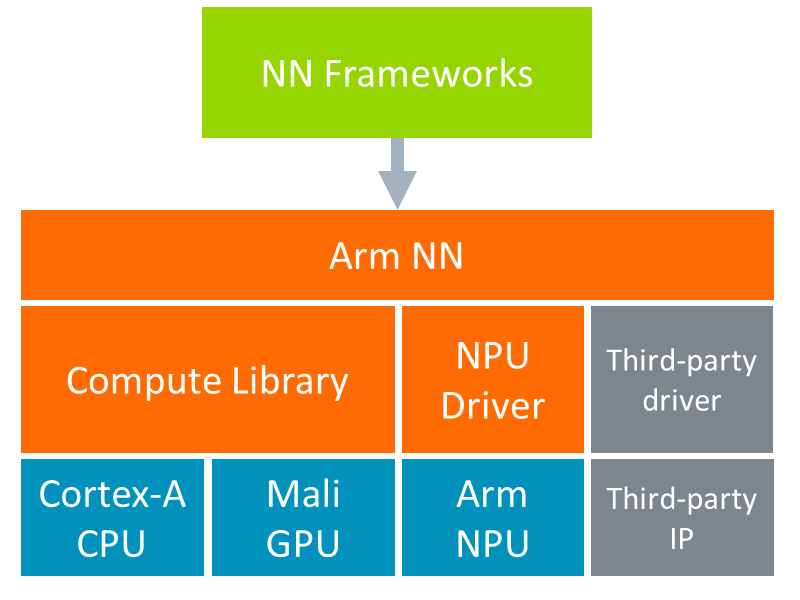
The 20.11 Release is intended to provide major improvements to usability and performance in addition to delivering some additional functionality. It can be found here in source code form.
The usability enhancements were:
- Added Debian packaging for ArmNN Core, TfLite Parser and PyArmNN to Ubuntu Launchpad. This means users on Linux no longer need to go through a source repository setup and compile in order to start working.
- Addition of TfLite Delegate as well as 21 of its most valuable operators. Allows a much larger set of models to be executed as operators that are not accelerated in the delegate will execute in the TfLite interpreter.
- Removal of the boost framework from all ArmNN code bar our unit tests. Simplifies deployment as the dependency on boost no longer exists.
- Website updates (better layout and more examples).
The performance enhancements were:
- ArmNN integration of Compute Library Activation and Batch Normalization fusing.
- ArmNN exposed the Compute Library fastmath option as a parameter that can be set on a per model basis and in some scenarios will result in the selection of a faster convolution algorithm at the cost of some accuracy (winograd).
The additional functionality was:
- Addition of high priority partner requested Logical AND/OR/NOT operators in NNAPI.
- Support for Android R, verified against CTS 11_r3 (Build Id: 20201114.173303).
- Added support for the EfficientNet-Lite Model.
New Features:
- Added Debian packaging, which allows ArmNN to be installed via our APT repository on Ubuntu’s Launchpad.
-
Added ability to turn on the Compute Library fast_math option through ExecuteNetwork and the Android-nn-driver.
- Using the fast_math flag can lead to performance improvements in fp32 and fp16 layers but at the cost of some accuracy.
- The fast_math flag will not have any effect on int8 performance.
- Added support for Logical NOT, AND and OR for CpuRef, CpuAcc and GpuAcc.
- Added optimization to fuse BatchNorm into Convolution and Depthwise Convolution in fp32 and fp16.
-
Added backend specific optimization to fuse Activations into the previous workload.
- Currently Activations can be fused with Addition, BatchNorm, Convolution, Depthwise Convolution, Division, Multiplication or Subtraction workloads on both CpuAcc and GpuAcc.
- Not all workloads can support all Activations.
- Added AddBroadcastReshapeLayer as optimizer.
- Added Map layer and Map workload. This layer has 1 input slot and 0 output slots and simply calls ->Map() on the input tensor handle.
- Added Unmap layer and Unmap workload. This layer has N input slot and 0 output slots and simply calls ->Unmap() on the input0 tensor handle. The remaining inputs are used for determining scheduling dependencies.
- Added support for TfLite Delegate (More information below in TfLite Delegate section).
TfLite Parser:
- Remove AddBroadcastReshapeLayer from TfLite Parser and added to optimizations.
- TfLite version updated to 2.3.1.
Tf Parser:
- Tensorflow version updated to 2.3.1.
- Add support for 2nd input to ExpandDims in TfParser.
ArmNN Serializer:
- Added support for Logical NOT, AND and OR.
Public API Changes:
Backend API Changes:
ExecuteNetwork App Changes:
- Added ability to enable Compute Library fast_math through ExecuteNetwork.
- Added ability to execute models using TfLiteDelegate.
- Refactored ExecuteNetwork to support cxxopts.
- Allow use of dynamic backendId in execute network.
Other changes:
-
Removed remaining boost from ArmNN runtime code (Boost still resides in Unit Tests).
-
Removed boost::format and swapped to fmt
- Link fmt statically and change to be header-only interface library
- Removed boost::tokenizer and boost::escaped_list_separator to avoid use of CsvReader
- Removed boost::make_iterator_range and boost::to_upper_copy
- Removed boost::transform_iterator and make_transform_iterator
- Removed boost::numeric_cast
- Removed boost::math::fpc uses
- Removed boost/preprocessor.hpp
- Removed boost::program_options and swapped to cxxopts
- Removed boost::variant and swapped to mapbox/variant library
- Removed Boost from standalone dynamic backend
- Removed remaining Boost references from test executables
-
- Extended dump file with info about fused layers.
- Added SECURITY.md file that contains the security policy, vulnerability reporting procedure and a PGP key that can be used to create secure vulnerability reports.
- Graph::Print() now outputs more information such as number of input/output tensors and tensor dimensions.
- Updated Protobuf to 3.12.0.
- Load dynamic backends for YoloV3 tests.
- Included layer GUID in SerializeToDot output.
- Refactored Optimize(…) function to throw exceptions instead of returning null.
- Speed up the reference backend.
- Added int32 and int64 ArgMax op support.
- Added Quantization operator=() function to Tensor.
-
Introduce ModelOptions to OptimizedNetwork.
- Added ability to pass ModelOption through Network::LoadNetwork() to Workload factory.
- Added Load-scope dynamic tensor TfLite tests.
Bug Fixes:
- Fixed Unittest failure while building using EthosNAcc backend.
- Fixed crash on model with Fullyconnected Sigmoid Activation by adding supported activations check to Neon FullyConnected validate.
- Fixed logical VTS skip.
- Fixed issue where EthosNAcc backend would output all zeros when falling back to CpuRef.
- Fixed issue causing SSD Mobilenet f16/uint8 to fail on CpuRef via ExecuteNetwork.
- Fixed issue with signed-int8 quantized model.
- Fixed error running EfficientNet-Lite on GpuAcc.
- Fixed validation for per-channel quantization.
- Fixed segfault between Neon and Cl layers.
- Fixed NonMaxSuppression.
- Fixed Yolov3 producing 0s on Neon.
- Removed Resize from list of layers that need padding in Neon.
- In Neon and CL MUL workloads, use as convert policy SATURATE if one of the inputs is quantized and WRAP for the rest of cases.
- Fixed non-channel per axis quantization.
- Fixed compiler implicit copy deprecation warning by updating Quantization copy constructor.
- PyArmNN has hard dependencies on all parsers when using cmake.
- Fixed cxxopts and ghc cross compilation issue.
- Fixed undefined reference to GetIdStatic() in DynamicBackendsTests.
Known Issues:
- Using a comma separated list to specify multiple compute devices
--compute CpuRef,CpuAccwhen using ExecuteNetwork doesn’t work. To use multiple compute devices use--compute CpuRef --compute CpuAcc.
TfLite Delegate:
New Features:
Current supported operators:
- Activation (ReLu, Relu6, Logistic, and TanH)
- Comparison (Equal, Greater, GreaterOrEqual, Less, LessOrEqual, NotEqual)
- Control (Concat and Mean)
- Convolution (Convolution2d, DepthwiseConvolution2d and TransposeConvolution)
- ElementWiseBinary (Add, Div, Max, Min, Mul, Sub)
- ElementWiseUnary (Abs, Exp, Neg, Rsqrt, Sqrt )
- FullyConnected
- Pooling (MaxPool2d, AveragePool2d and L2Pool2d)
- Quantization (Dequantize and Quantize)
- Redefine (Reshape)
- Resize (Bilinear and NearestNeightbour)
- Softmax (Softmax and LogSoftmax)
- Transpose
Other Changes:
- Created the TfLite Delegate sub-directory in ArmNN.
- Added Fp16 support.
- Updated Tensorflow from v1.15 to v2.3.1.
- Activated compiler warnings when building delegate.
- Added ability to execute models through ExecuteNetwork using the TfLiteDelegate.
Known Issues:
Build dependencies:
| Tools | Version we support |
|---|---|
| Git | 2.17.1 or later |
| SCons | 2.4.1 (Ubuntu) and 2.5.1 (Debian) |
| CMake | 3.5.1 (Ubuntu) and 3.7.2 (Debian) |
| boost | 1.64 |
| Tensorflow | 2.3.1 |
| Caffe | tag 1.0 |
| Onnx | 1.6.0 |
| Flatbuffer | 1.12.0 |
| Protobuf | 3.12.0 |
| Eigen3 | 3.3. |
| Android | 10 and 11 |
| Mali Driver | r25p1_01bet0 |
| Android NDK | r20b |
| mapbox/variant | 1.2.0 |